It’s been a while since the last update, so this’ll be a big splurge on the implementation of Pathfinding on my killbot.
Starting with a quick explaination of A* pathfinding. A* is a method based on Dijkstra, except A* has the addition of heuristics (a method of determining distance) to quicken the algorithm.
A* has a node system to calculate the quickest path. The nodes could be anything from polygons to manually created points in the world. A* checks what the quickest path is by adding nodes to an “open list”, and checking how close that node is to the end, and how “expensive” it was to move there (expensive in terms of time and effort).
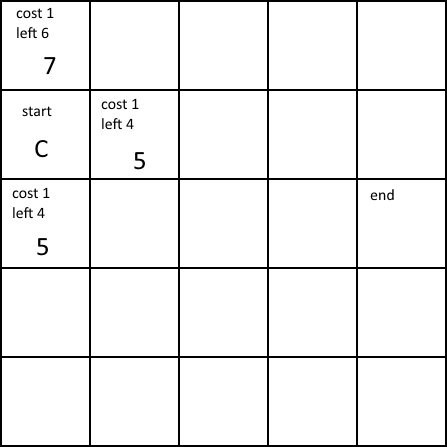
For example, we have our start and end point on a grid (assuming every grid is a node). The “cost” of each node is 1 for every node, and what’s “left” is how many squares towards the end from that point. The adjacent nodes are added to the open list, and the open list is checked to see which number is lowest. The node with the lowest number is the more efficient. As we can see two nodes are the same, one is randomly chosen.
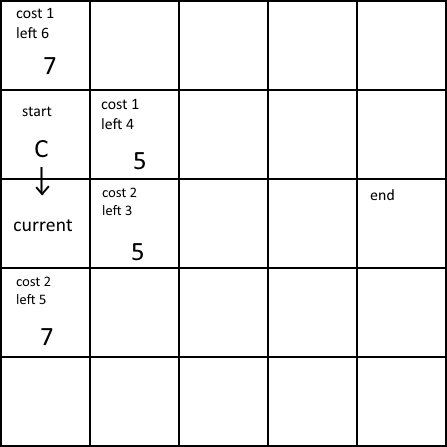
Now the starting node is closed, so that the algorithm doesn’t check the value, and the nodes adjacent from the current one are opened. The current node makes a note of the node it came from, or its parent, indicated by the arrow. Again, we have two nodes with the same values, so one is chosen.

The number stays the same, because the distance travelled is rising while the distance to the target is lowering.
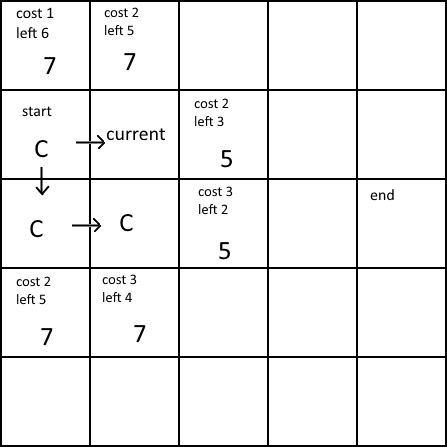
Going to the other node, we can see that both are as efficient as each other. The path that will be used will be determined by how “randomly” the nodes are chosen. In my case, is the first node in the list.
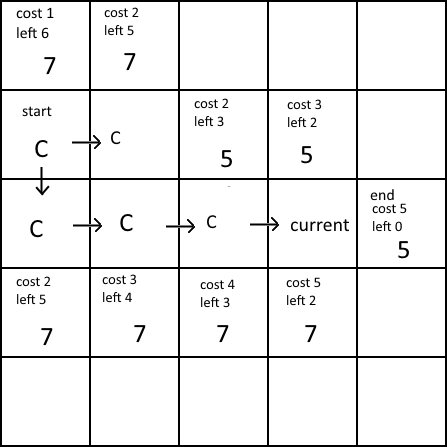
Eventually we get to the end. We can then trace back the path by following the chain of parents to get back to the start.
And that’s A*. The method of getting the heuristics can vary, in this case it was Manhattan distance. Dijkstra is a similar method, except there is no concept of “how close am I” in the nodes. Dijkstra will fill the entire map with information, then calculate which path has the lowest cost to move onto to the end.
My next post will be about how I implemented A* into my killbots program.

One thought on “Studio 2: An explanation on A*”